With C language, elements are stored and aligned along rows. To create a 2D array (here with double type), noted x0 with size_x number of rows and size_y number of columns, we allocate first an array x0 of size_x rows and do another allocation of size equal to size_x*size_y : address of first element is located at x0[0]. Then, we link each x0[i] to the right address of block. Here is this snippet code :
// Declaring double pointer for 2D array
double **x0;
// Allocating array
x0 = malloc(size_x * sizeof(*x0));
x0[0] = malloc(size_x * size_y * sizeof(**x0));
// Making 2D array contiguous
for (i = 1; i < size_x; i++)
x0[i] = x0[0] + i * size_y;
After this code snippet, you can initialize x0 array since (i,j) element is reachable with x0[i][j] notation.
Using 2D contiguous arrays are helpful for example in MPI applications, where rows or columns are exchanged between different processes : this operation only works for contiguous arrays.
// Loop on rows
for (i = 0; i < size_x; i++)
{
// Allocating size_y columns for each row
x0[i] = malloc(size_y * sizeof(**x0));
// Loop on columns
for (j = 0; j < size_y; j++)
{
// Incrementing size_z block on x0[i][j] address
x0[i][j] = x0_alloc;
x0_alloc += size_z;
}
}
After this code snippet, you can initialize x0 array since (i,j,k) element is reachable with x0[i][j][k] notation. Similary with 2D case, 3D contiguous array are used in MPI applications, where we exchange matrixes between different processes : this functionality requires arrays to be memory aligned.
One can produce with only one command line a data flow which can be directly piped into gnuplot. For example, you can see below how to plot the function $y=\cos(x)$ avec $0 < x < 10$ :
seq 0 0.1 10 | gnuplot -p -e 'plot "-" u 1:(cos($1)) w l'
"seq 0 0.1 10" command generates a column of data contained into range [0,10] spaced with a step equal to 0.1. Then, we pipe this data flow into gnuplot using -e option (gnuplot executes commands passed as parameters) and -p option (plotting window still appears after commands executed). Make sure to respect the order for these options, i.e -p -e.
Other solution with "awk" function - Plotting function $y=x^{2}$ :
seq 0 0.1 10 | awk '{printf("%3f\t%3f\n", \$1, \$1^2)}' | gnuplot -p -e 'plot "-" u 1:2 w l'
To replace commas by dots for floating numbers with non-US versions of Bash, don't forget to do : export LC_NUMERIC=en_US
In this section is presented a quick way to generate a Gaussian distribution. For this, one uses the random module of python :
for ((i=1;i<=10000;i++));do python -c"import random; print \min(10,max(0,random.gauss(5,1)))";done | \
gnuplot -p-e"set terminal png size 550,384 font 'Helvetica,9'; \set tics font 'Helvetica,8'; set output 'gaussian.png'; \set style data histograms; set style histogram cluster gap 1; \set style fill solid border 3; set boxwidth 0.1; binwidth=0.1; \bin(x,width)=width*floor(x/width) + width/2.0; set xrange[0:10]; \plot '-' using (bin(\$1, binwidth)):(1) smooth frequency with boxes \title '{Gaussian distribution}'"
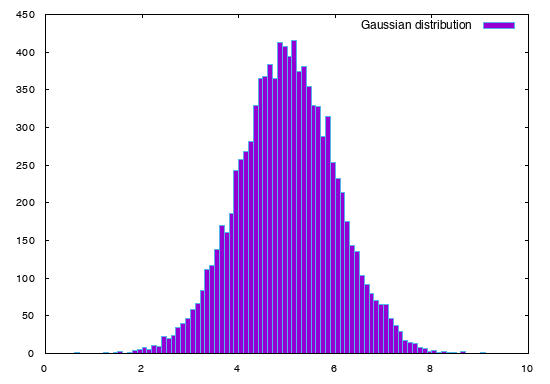
Below an example of sample obtained with $\mu=5$ and $\sigma=1$ :
Figure 1 : Example of Gauss(5,1) sample with 10000 random values into range [0,10]
If one wants to save histogram values into a file, one has to do :
set table 'hist.dat'; \
plot '-' using (bin(\$1, binwidth)):(1) smooth frequency with boxes; \unset table;"
Le déroulage de boucles ("unrolling loops" en anglais) est une technique d'optimisation de code qui consiste à dupliquer le corps d'une boucle afin de limiter la répétition de l'instruction de saut. Voici ci-dessous un exemple de code qui met en évidence le gain obtenu sur le runtime pour une simple boucle. Pour cela, nous incluons le code assembleur dans un source C, ce qui permet d'utiliser la fonction gettimeofday() pour mesurer le temps d'exécution passé dans cette boucle :
Tout d'abord, le code C dans lequel nous incluons du code assembleur, sans déroulage de boucles ni autres optimisations (fichier loop-without-unroll.c) :
#include <stdio.h>#include <sys/time.h>#include <unistd.h>int main ()
{
// Init sumint sum = 0;
// Number of iterationsint n = 100000000;
struct timeval tv1, tv2;
longint diff;
// Start time
gettimeofday (&tv1, NULL);
// Loop with Sparc assembly into C sourceasmvolatile ("clr %%g1\n\t""clr %%g2\n\t""mov %1, %%g1\n"// %1 = input parameter"loop:\n\t""add %%g2, 1, %%g2\n\t""subcc %%g1, 1, %%g1\n\t""bne loop\n\t""nop\n\t""mov %%g2, %0\n"// %0 = output parameter
: "=r" (sum) // output
: "r" (n) // input
: "g1", "g2"); // clobbers// End time
gettimeofday (&tv2, NULL);
// Compute runtime for loop
diff = (tv2.tv_sec - tv1.tv_sec) * 1000000L + (tv2.tv_usec - tv1.tv_usec);
// Print results
printf ("Elapsed time = %d usec\n", diff);
printf ("Sum = %ld\n", sum);
return0;
}
Remarques sur l'inclusion pour gcc de code assembleur Sparc dans un source C :
Doubler le symbole "%" devant chaque nom de registre
"%0" correspond au paramètre de sortie
"%1" correspond au paramètre d'entrée ("%2" au deuxième, "%3" au troisième, etc ...)
La syntaxe, pour faire le lien entre les variables du source C et les registres, est la suivante :
: "=r" (sum)
: "r" (n)
: "g1", "g2"
où la première ligne correspond au paramètre de sortie ("sum"), la deuxième au paramètre d'entrée ("n") et la dernière aux registres "clobbered", c'est-à-dire les registres qui seront modifiés durant l'exécution du code assembleur (ici les registres "%g1" et "%g2").
ps : join like me the Cosmology@Home project whose aim is to refine the model that best describes our Universe