Caution : for previous versions before 05/23/18, bug fixed on convergence criterion (Space step $h$ mus be square powered and not third)
Make sure at the execution of parallel code (with "mpirun" command) that number of processes equals to product of subdomains number along x by subdomains number along y and along z ( "x_domains", "y_domains" and "z_domains" parameters in "param" input file ) :
We get the same relations for $y$ variable. By taking $h_{x}=size_{x}/N_{x}$, $h_{y}=size_{y}/N_{y}$, $h_{z}=size_{z}/N_{z}$ and with convention $\theta(x_{m},y_{m},z_{m})=\theta[i][j][k]$, we have :
This formula is implemented in this way for the C language parallel version (cf explUtilPar.c file) ; You can notice that xs, xe, ys, ye, zs, ze (with "s" for "start" and "e" for "end") variables represent the coordinates of the subdomain corresponding to the current process of rank "me" :
// Perform an explicit update on the points within the domain
for (i=xs[me];i<=xe[me];i++)
for (j=ys[me];j<=ye[me];j++)
for (k=zs[me];k<=ze[me];k++)
x[i][j][k] = weightx*(x0[i-1][j][k] + x0[i+1][j][k] + x0[i][j][k]*diagx)
+ weighty*(x0[i][j-1][k] + x0[i][j+1][k] + x0[i][j][k]*diagy)
+ weightz*(x0[i][j][k-1] + x0[i][j][k+1] + x0[i][j][k]*diagz);
Convergence criterion links the exact solution with the numerically computed solution. If we have $h_{x}=h_{y}=h_{z}=h$, explicit schema \eqref{eq9} is steady if :
We are going to breakdown domain (also named grid) into subdomains assigning for each one a process. Gain on runtime is achieved since computing iterative schema is done parallely and updates for the 4 sides of a given subdomain is performed with communications of surrounding processes : we called this breakdown a "Cartesian topology of processes" because subdomains are squared or rectangular. Convention taken here, for indices of 2D arrays with both Fortran90 and C languages, is (i,j)=(row,column). Below an example showing the breakdown with 16 processes along x_domains=2, y_domains=4 and z_domains=2 :
Figure 1 : Ranks of processes with convention (row,column)$\,\equiv\,$(x_domains,y_domains) and z_domains dimension
With Fortran, elements of 2D array are memory aligned along columns : it is called "column major". In C language, elements are memory aligned along rows : it is qualified of "row major".
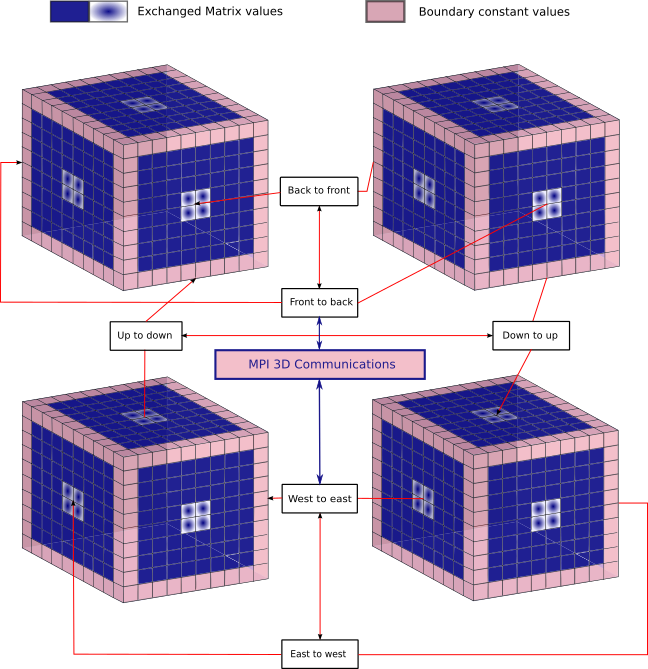
Parallelization is done using communications between the processes of each subdomain. As we can see in the code snippet below, for a given iteration process with rank "me", we compute the next values to the corresponding subdomain with "computeNext" function, then we send with "updateBound" each face of cubes (see figure below), i.e matrixes, to processes located in North-South, East-West and Front-Back of the current process "me".
// Until convergence
while(!convergence)
{
step = step + 1;
t = t + dt ;
// Perform one step of the explicit scheme
computeNext(x0, x, dt, &resLoc, hx, hy, hz, me, xs, ys, zs, xe, ye, ze, k0);
// Update the partial solution along the interface
updateBound(x0, neighBor, comm3d, column_type, me, xs, ys, zs, xe, ye, ze,
xcell, ycell, zcell);
// Sum reduction to get error
MPI_Allreduce(&resLoc, &result, 1, MPI_DOUBLE, MPI_SUM, comm);
// Current error
result= sqrt(result);
// Break if convergence reached or step greater than maxStep
if ((result<epsilon) || (step>maxStep)) break;
}
The following figure shows an example of communication for a breaking down of global domain into 8 subdomains, which means with 8 processes. Actually, only one plane of 4 processes is visible, one has to imagine a second parallel plane to this one in order to represent all 8 subdomains :
Figure 2 : Example of communications between 8 processes
Like in 2D case, note that ghost cells are initialized at the beginning of code to the constant value of the edge of the grid.
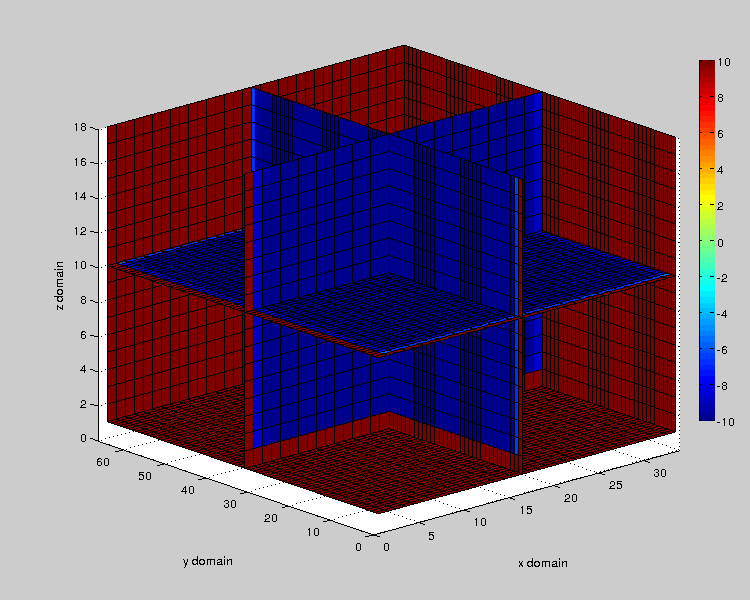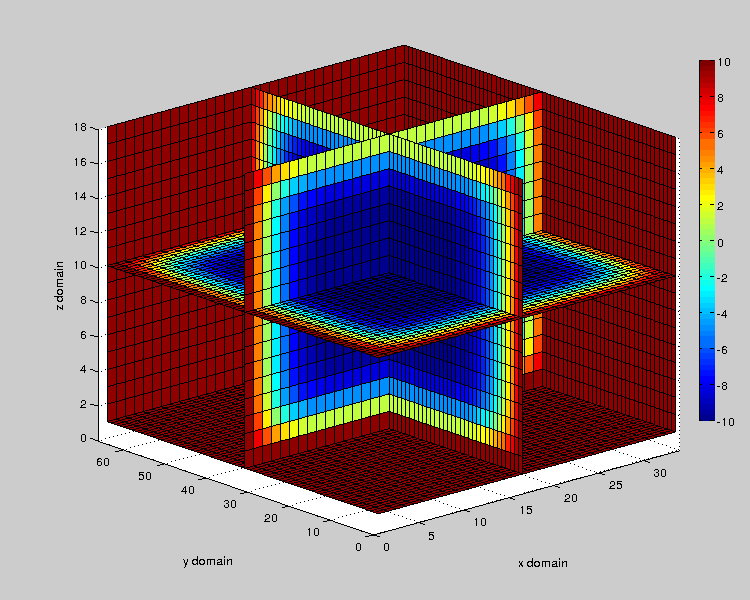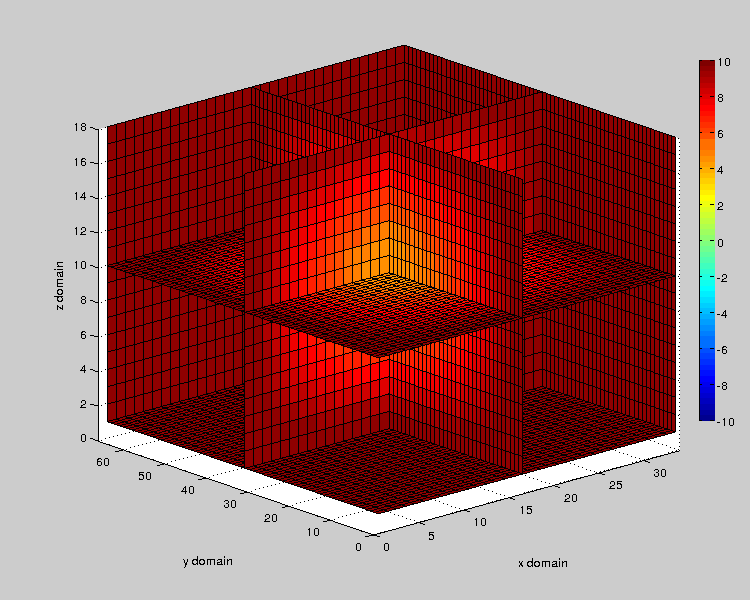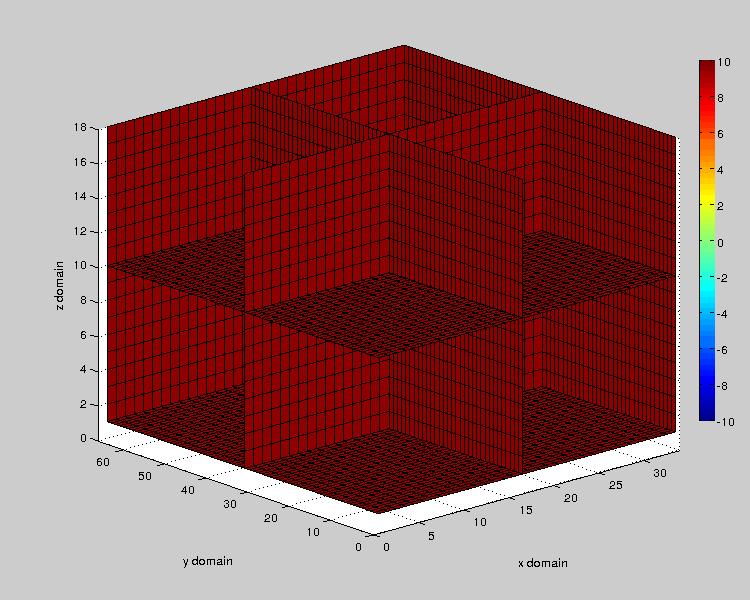
To get an animated gif showing the temporal evolution of diffusion, we need output data files at different time intervals. We use this script generate_outputs_heat3d which will generate it. Then, we use the Matlab script generate_gif_heat3d.m to generate a gif file. Here is an animation of a slice plot made with a 32x64x16 mesh :
Figure 3 : Animated Gif showing temperature evolution on domain
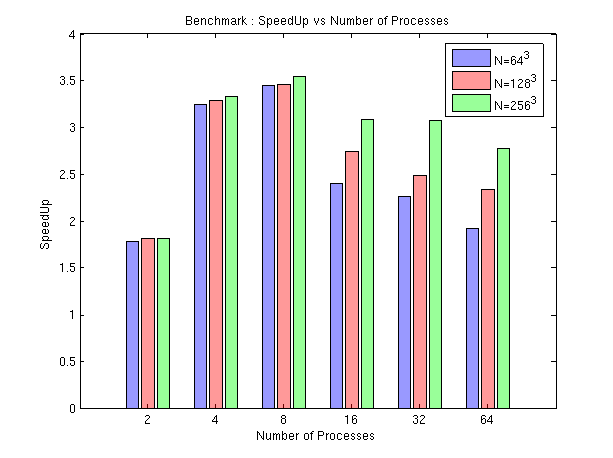
To evaluate the performance of the code, we do a benchmark by varying the number of processes for three different grid sizes (64^3, 128^3 and 256^3). The script run_performances_heat3d allows to get execution time for each of these two parameters.
Figure 4 : SpeedUp as a function of processes number and size of domain
Performance for one single process represents the execution of the sequential code. For a number of processes greater than 1 (parallelized versions), the runtimes are lower than the sequential version. We can see that the best performance is done with 8 processes, regardless of the size of the mesh. This could be explained by the fact that this benchmark has been achieved with 8-core i7 processor. Indeed, Core i7 implements "Hyper-Threading" : this multitasking technique allows a physical optimization for 8 processes and a logical optimization for a higher number of processes.
ps : join like me the Cosmology@Home project whose aim is to refine the model that best describes our Universe