We describe in this section the GPU version of Sum Reduction with OpenCL-1.x : the goal is to get the summation of all elements of a 1D array. We will present the Kernel Code used and make comparative tests of performance with CPU release for different array and Work-Group sizes. We have to notice that "Sum Reduction" built-in functions already exist into OpenCL-1.x (based on atomic function atom_cmpxchg) but they are not very efficient : the ones used in OpenCL-2.x will be more high-performing. So this is here a pedagogical example which can be useful to understand a way of parallelize a sequential code with all OpenCL API functionalities. Sources can be donwloaded from this link :
Kernel code into OpenCL is the core of all GPU parallel processing. It performs the main part of performance gain compared to the sequential version. In structure of a OpenCL code, processing is splitted into Work-Group and for each of these groups, variables declared as local are shared by all threads of the Work-Group : we call it "local memory" in opposition of "global memory" which makes reference to Work-Items, i.e the total number of calls of Kernel Code, each representing a thread.
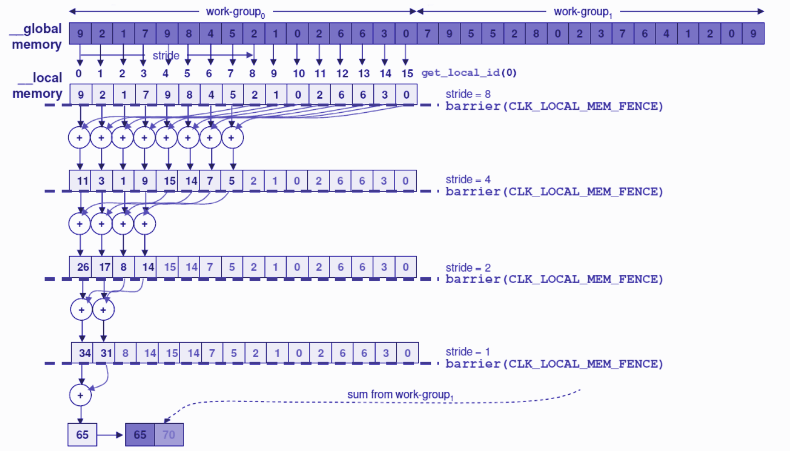
Strategy is to use this shared memory by copying values from global area into a same Work-Group : then, this latter is divided into two parts (with size "stride") and we add elements of each subgroup side by side with an offset equal to "stride". We redo the same operation after dividing by 2 the previous subgroup. This process is repeated until "stride" size is less than 1. Below figure illustrates the algorithm :
Inside a Work-Group, synchronizing all threads is necessary. Indeed, before doing again another iteration (i.e another division by 2), we have to make sure that all "stride" partial sums have been achieved. This synchronization inside a same Work-Group is carried out with barrier(CLK_LOCAL_MEM_FENCE) instruction.
// Copy from global to local memory
localSums[local_id] = input[get_global_id(0)];
// Loop for computing localSums : divide WorkGroup into 2 parts
for (uint stride = group_size/2; stride>0; stride /=2)
{
// Waiting for each 2x2 addition into given workgroup
barrier(CLK_LOCAL_MEM_FENCE);
// Add elements 2 by 2 between local_id and local_id + stride
if (local_id < stride)
localSums[local_id] += localSums[local_id + stride];
}
// Write result into partialSums[nWorkGroups]
if (local_id == 0)
partialSums[get_group_id(0)] = localSums[0];
}
At the end of Kernel processing, we get an array containing the partial sums of each Work-Group. So one has to compute the sum of partialSums array elements : we can do it with CPU or GPU. To get a better speedup, we chose to perform this final summation by CPU; indeed, using GPU built-in atomic functions (like based on atom_cmpxchg), runtime gain is not fair from an optimization point of view. This will be interesting to compare these performances with atomic functions of OpenCL-2.x.
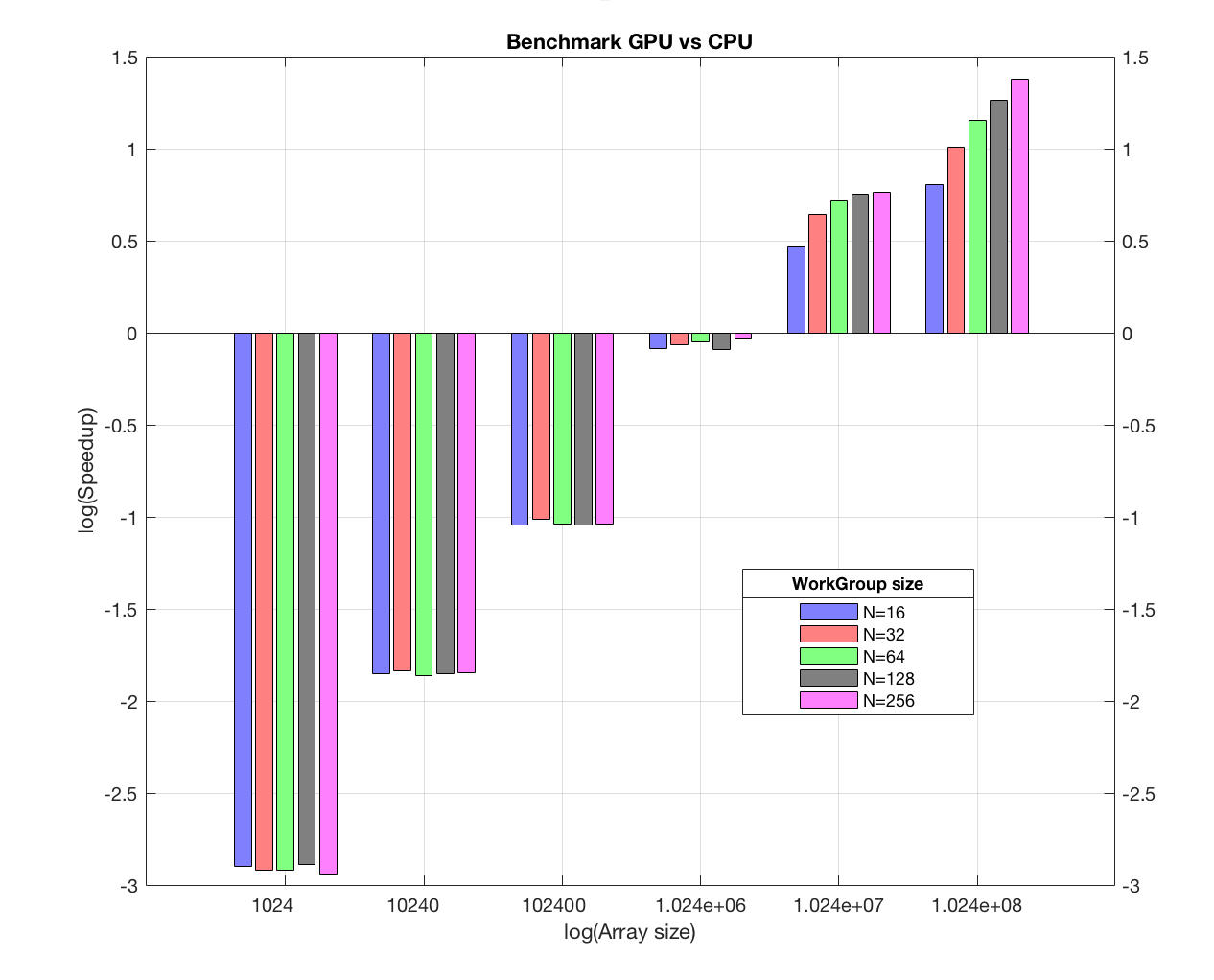
We accomplish a benchmark between GPU and CPU (sequential) version for different array and Work-Group sizes. It has been done with a AMD Radeon HD 7970 graphics card. The shell script run_performances_sumGPU allows to do batch execution in order to produce speedups as a function of input parameters. Below the results of this evaluation plotted with Matlab script plot_performances_sumGPU.m :
Figure 1 : SpeedUp GPU vs CPU as a function of array and WorkGroup sizes
Best performances gain of OpenCL parallelization is reached for array size higher than 1 Million. For speedup upper to 1, best performances are reached with a Work-Group size equal to 256. Given in this case dimension is big, we have to choose a limited number of Work-Group (numWorkGroup = NworkItems/sizeWorkGroup) and this is done by setting a maximum value for sizeWorkGroup (our hardware has a limit of 4100 for sizeWorkGroup). At last, for a 100 Million array size, we get the best speedup, equal to 25.
Reduction operations (like sum of all elements, finding the maximum or minimum element, or finding the index of the maximum or minimum element of a vector) are widely used in conception of algorithms. We have restricted our study for the case of only one iteration : this can be extended to iterative schemes where we need to repeat, inside a main loop, the sum reduction of a modified array. Actually, one has to call "clEnqueueNDRangeKernel" function in this loop and use after "clSetKernelArg" with the new array as argument. For higher dimensions (than 1 Million), we expect to get a significant gain on runtime.
ps : join like me the Cosmology@Home project whose aim is to refine the model that best describes our Universe