1.Introduction :
Below two simple examples, with C-POSIX and GO languages, which show how to do parallel loops for computing $\pi$ with Monte-Carlo method :
to compile POSIX version and run it (first argument : number of processes and second : number of iterations) :
\$ gcc -lpthread pi_mc_pthread.c -o pi_mc
\$ ./pi_mc 10 100000000
# Estimation is 3.14212320
# Number of trials = 100000000
# Elapsed Time: 0 seconds 763061 micro ellapsed
|
to compile GO version and run it :
\$ go build pi_mc.go
\$ ./pi_mc 10 100000000
# Estimation is 3.141473
# Number of trials = 100000000
# Elapsed Time: 1 seconds 206985 micro ellapsed
|
Make sure at the execution that number of iterations is divisible by number of processes.
2.Benchmark :
Following histogram represents performances of POSIX (magenta palette) and GO (gray scale) codes. For this, we plot the log inverse product of precision got on $\pi$ by runtime. This interval relies itself on the number of iterations (size of loop on abscissa) and the number of processes (in the range $2^0=1$ to $2^{12}$ by step $2$).
The bash script to get runtimes is available on run_benchmark_pi, with 'posix' parameter for POSIX version and 'go' for GO version. To make the figure below, here this Matlab script : plot_benchmark_pi.m.
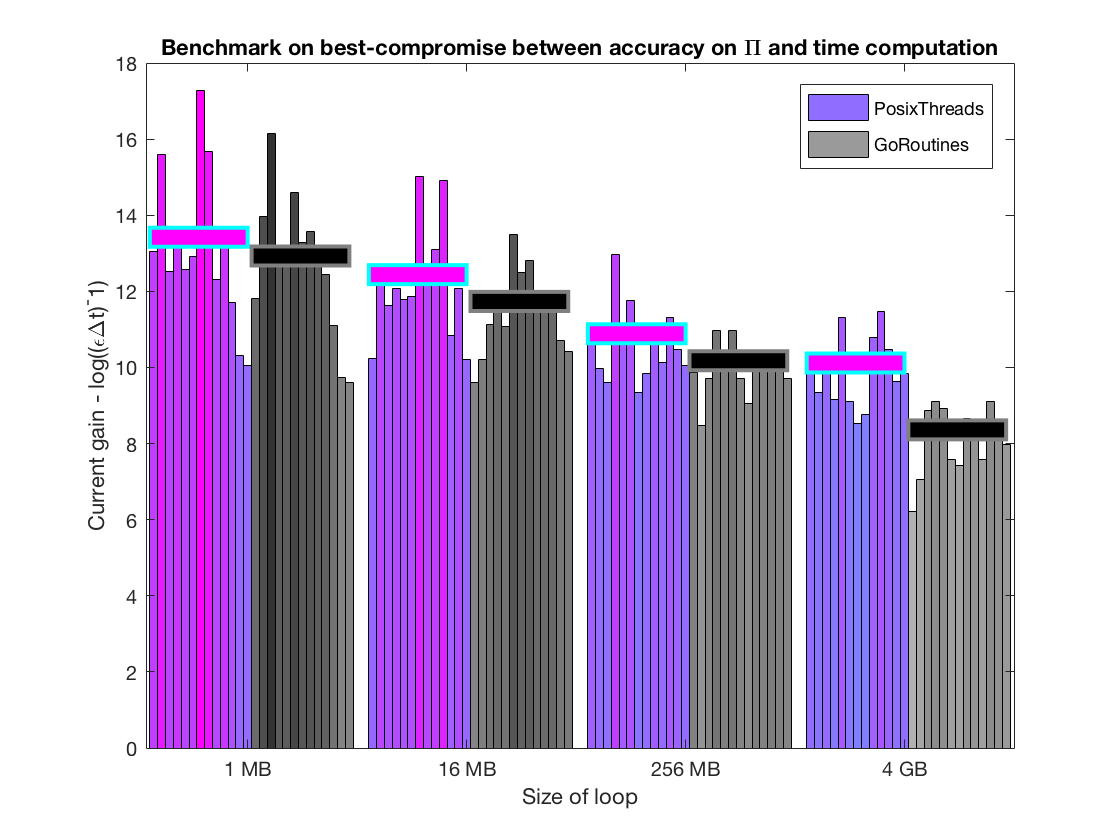
We already know that estimator of $\pi$ value is as more accurate as sample is big, i.e when number of iterations is high. So we want to evaluate precision gain as a function of runtime. . Horizontal rectangles represents the average performances, for each group of size loop, with both versions. We notice then that accuracy increases relatively less quick than runtime.
For POSIX version, a good compromise is done with N_iterations = 1MB and N_process = 64, whereas for GO version, we get the best performance with N_iterations = 1MB and N_process = 8.
Finally, from a hardware implementation point of view, POSIX version gives faster results with a runtime gain of 33.91% compared with GO version. This can be explained by the fact that GO version uses another system layer, unlike C language wich is the system language of Linux.
|




